
Are you missing key networking metrics?
Is your fancy service mesh consuming too many resources?
Hey Pixelers,
Ok, now the hype is out of the way, lets get into the details.
What is a Kernel?
A computer kernel is the core component of an operating system that manages system resources, provides abstractions for hardware, and enables communication between software and hardware components. Linux itself is just a Kernel, with your distribution providing the Operating System as a package. The kernel is additionally responsible for managing system resources and ensuring that each process or application has access to the resources it needs to run. It also provides security mechanisms, such as user and file permissions, to protect the system and user data. In order to achieve all this the kernel operates in a privileged mode, which means that it has direct access to the computer's hardware and can perform tasks that regular user-level programs cannot.
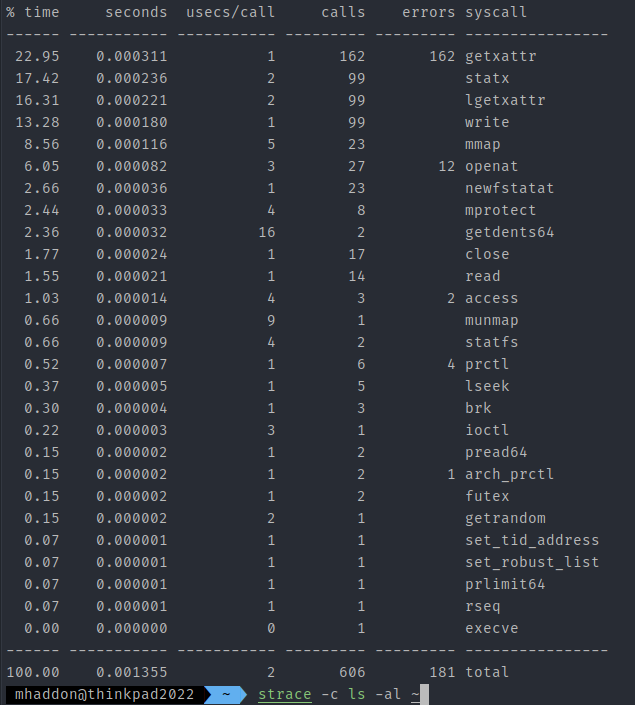
You might think that the Kernel therefore is not doing much. If all our logic is in our application, surely the Kernel is just for some random processing here and there? Well, let me put it this way, a simple ls command in a small directory, causes over 600 kernel calls. You can imagine that the Kernel is acting as a middleman for pretty much everything.
Even though Linux is the most famous Kernel, it is not the only one, there are many, with the Windows NT Kernel being another popular choice... Foreshadowing..
Implementing Observability
Now, lets say we want to build a tool to observe our system. We can build it with our application, but then we will need to create different observability implementations for each application type. We could create new abstraction layers, which lie below our applications, and observe upon everything above it. This is one of the benefits of service meshes. Or, we could tap into the very heart of the computer, and create standard central observability tooling, right in the Kernel.
The last one obviously sounds like the most attractive...
Until you realise that Kernel changes can take years, and that is not even taking into consideration the length of time that your distribution will need to integrate these changes. That is of course, assuming the Kernel will even want your changes. We could instead, write our own custom Kernel Modules, however, how many Kernel engineers do you know? As mentioned before, the Kernel has privileged access to everything on the computer, the ability to crash or steal everything. I don't know about you, but I am not looking forward to the call at 3am where a Cassandra cluster is crashing due to a glitchy Kernel module. And if I wrote that Kernel module, then that cluster would be definitely crashing.
But, what if we had a way of extending the kernels behaviour, in a way we can trust.
eBPF Verifier
The eBPF Verifier is the technology that makes eBPF interesting. It ensures the safety of the kernel by enforcing a set of rules to determine whether eBPF programs are safe to run in the kernel. When an eBPF program is loaded into the kernel, it goes through the verification process, which involves analyzing the bytecode and ensuring that it conforms to the eBPF instruction set and that it doesn't violate any kernel rules that could cause system instability or security issues.
The verifier analyses the eBPF program's control flow to ensure that the application is considered safe. For example:
- Detect and disallow infinite loops
- Detect and disallow de-referencing of null pointers
- Detect and disallow applications with unreachable instructions
- Detect and disallow accessing of memory outside the programs allocated range
- Detect and disallow accessing methods and data that are outside the programs context, defined by the program type
- Detect and disallow unbounded recursion
- Detect and disallow stack overflows, program must stay within their allocated stack space
- Detect and disallow invalid usage of data types
In short, it ensures that, regardless of input, that the program will always terminate safely. This is essential, as a crash in the Kernel will be catastrophic.
This does not mean we can just install any sort of ebpf program, as it can still be used for malicious intent. I would only trust ebpf programs, that you would not mind giving production root access to. Even though the above list is pretty extensive, and I am sure there is much more security features of this technology, I will emphasise the trust concern as I am sure we will find various security holes over the coming years, So let's not get too ahead of ourselves and let's wait before we dump our node_modules into our Kernel.
Now, we cant just write our program in any language, as our program needs to have its bytecode verified by the eBPF verifier, however the choice between C and Rust is already probably the majority of languages you would expect to write something like this in.
eBPF
These dynamic programs can be loaded and unloaded from the kernel with ease. Once attached to an event, they spring into action, no matter the root cause! Imagine attaching a program to the syscall for opening files - it will activate every time any process opens a file, regardless of whether the process was already running when the program was loaded. No restart required.
Interestingly, as the foreshadowing prepared you, Microsoft is also working on a project called "ebpf-for-windows", which advertises a level of cross-compatibility: "The intent is to provide source code compatibility for code that uses common hooks and helpers that apply across OS ecosystems." ... so, that sounds pretty cool.
What is the fuss?
We can now create company-specific eBPF programs, no waiting on kernel maintainers required, in-fact, lets look at what some companies have done with eBPF:
Facebook has created Katran, a highly scalable network load balancer that uses eBPF for packet filtering and processing, enabling it to achieve high performance and scalability. Netflix has created programs to gain detailed visibility into their network traffic and performance, allowing them to detect anomalies, troubleshoot issues, and improve network performance at scale. Google, Amazon, Intel and Microsoft have created eXpress Data Path, which filters traffic at the network interface level using eBPF, allowing for efficient and effective DDoS protection.
This is a small list of examples, in reality, each of these companies is actually running multiple ebpf programs on each node.
Before we get too excited, and rewrite our companies coffee grinder cloud integration with eBPF... Remember, do you really want to be debugging your program with print statements, after cutting off your only supply of caffeine? The current toolset surrounding eBPF is still quite limited, the visibility of the programs state is obscure, and you need engineers skilled with eBPF in order to diagnose faults. I expect, and hope, this to all change in the near future.
So when can I start killing all my sidecars?
There is a lot of drama that eBPF will kill sidecars and service meshes. Maybe, I am not going to make a declaration into the distant future, but not for a long time. If you are a smaller organisation, trying to save on money, than I would recommend you investigate utilising eBPF as a source for companies metrics as it is more light-weight. Not all organisations need the added abstraction of a service-mesh. Cilium is great for this purpose. I have already had success replacing the metrics provided by Istio for Cilium, in order to limit the resource overhead in the cluster.
However, the downside of eBPF is the same as its benefit, the authoritarian gatekeeper of code quality, limits the ability for eBPF to work with higher-abstractions. Layer 7 protocols, like HTTP and mTLS, are like high-maintenance pets that are already tough to handle in a forgiving household. The thought of trying to train them to behave in eBPF's restricted realm seems about as practical as teaching a cat to fetch.
A better way to think about eBPF and service meshes, is that eBPF will assist service meshes in becoming more powerful. An eBPF enabled Service Mesh, would allow for the benefits of both worlds. It would allow for the performance benefits of eBPF at the lower levels, while providing a proxy and agent running in userspace for the more nasty higher abstractions. We could run the proxy on each node, instead on each pod, but then the resource scaling is not necessarily linear according to the processing units. So probably the future is exactly the same as we have it now, just more efficient and with more features.
In a future video I think it would be fun to create our own little eBPF program together, maybe see if we can somehow crash the Kernel. I am also intending to do some deep-dives and analysis on popular eBPF integrated programs, such as Falco, Cilium, Pixie and more.
Thanks for checking out this video,
As always, hope you guys have a lovely day
Cheers
